
Understanding the Kubernetes Control Plane: A Deep Dive
Understand the control plane Kubernetes architecture and management essentials to ensure efficient and secure cluster operations.
Table of Contents
Kubernetes is now the standard for container orchestration, but its complexity can be challenging. The control plane Kubernetes, the core of your cluster, manages everything. From scheduling pods to security policies, understanding the control plane Kubernetes is crucial for smooth operations. This guide provides a clear overview of its architecture, key components, and best practices, exploring how it works, common challenges, and strategies for ensuring security and high availability. We'll also touch upon the Kubernetes control plane and its relationship to the Kubernetes data plane, and even how it fits within larger cloud control plane architecture concepts.
This guide provides a comprehensive overview of the Kubernetes control plane, covering its architecture, key components, and operational best practices. We'll explore how the control plane works, common challenges, and future trends, equipping you with the knowledge to effectively manage and optimize your Kubernetes deployments.
Unified Cloud Orchestration for Kubernetes
Manage Kubernetes at scale through a single, enterprise-ready platform.
Key Takeaways
- The Kubernetes control plane is the central nervous system of your cluster: The API server, scheduler, controller manager, etcd, and cloud controller manager work together to manage resources and maintain the desired state. Keep these components healthy for smooth application operation.
- Prioritize security and high availability: RBAC and network policies are essential for securing your control plane. Multi-master setups, load balancing, and regular backups ensure continuous operation. Proactive monitoring helps identify and address issues quickly.
- Prepare for the future of Kubernetes: Control planes are evolving to manage more than just containers. Focus on scalability, simplified management, and robust security to handle the increasing complexity of next-generation control planes.
Understanding the Kubernetes Control Plane
The Kubernetes control plane is the brain of your cluster, the central hub responsible for managing and directing all operations within the Kubernetes environment. It ensures your applications run smoothly and efficiently.
What is a Control Plane in Kubernetes?
The Kubernetes control plane is the brain of your Kubernetes cluster, the central command center responsible for keeping everything running smoothly. It constantly monitors the cluster's state, making decisions about where to run applications, how to scale them, and how to handle failures. A well-functioning control plane is essential for a stable and efficient Kubernetes environment.
Several key components make up the control plane, each with a specific role. The kube-apiserver acts as the front door, handling all incoming requests. The kube-scheduler determines where to run your pods, considering resource availability and other constraints. The kube-controller-manager ensures the desired state of your cluster matches the actual state, constantly adjusting resources. etcd, a distributed key-value store, stores the cluster's configuration data. Lastly, the cloud-controller-manager interacts with your cloud provider to manage resources like load balancers and storage.
Why is the Control Plane Important?
The control plane is crucial for effectively running a Kubernetes cluster. It ensures your applications run, scale, and communicate correctly. Without a healthy control plane, your applications might experience downtime, performance issues, or even total failure. A robust control plane is also vital for security, enforcing access controls and network policies to protect your cluster from unauthorized access and attacks.
Understanding the control plane is key to successfully managing Kubernetes deployments. Knowing how the components interact helps you troubleshoot issues, optimize resources, and ensure overall cluster health and stability. For example, slow application performance might lead you to investigate the kube-scheduler's efficiency. Resource constraint errors might prompt you to examine the kube-controller-manager's scaling activities. A deep understanding of the control plane empowers you to manage your Kubernetes environment and ensure smooth operation. For enterprise-grade control plane management and scaling, consider platforms like Plural.
Core Control Plane Functions and Components
The control plane's primary function is maintaining the desired state of your cluster. It does this through several key components:
- API Server (kube-apiserver): The front door to your cluster. All requests to manage or interact with Kubernetes resources pass through the API server. It's the central communication point for all other control plane components and external users. The API server validates and authorizes requests, ensuring only legitimate actions are performed.
- Scheduler (kube-scheduler): This component decides where your application workloads (pods) run. It considers factors like resource availability, node constraints, and data locality to optimally place pods across the worker nodes. The scheduler's decisions are crucial for efficient resource utilization and application performance.
- Controller Manager (kube-controller-manager): A collection of individual controllers that continuously monitor the cluster's state and take corrective actions to maintain the desired state. For example, if a pod fails, the controller manager detects this and launches a replacement. These controllers are essential for cluster stability and self-healing.
- etcd: A distributed key-value store holding the cluster's state information. All configuration data, application deployments, and other critical information are stored in etcd. Its distributed nature ensures high availability and data consistency.
- Cloud Controller Manager (cloud-controller-manager - optional): This component interacts with your underlying cloud provider to manage cloud-specific resources like load balancers and storage volumes. It bridges Kubernetes and the cloud infrastructure.
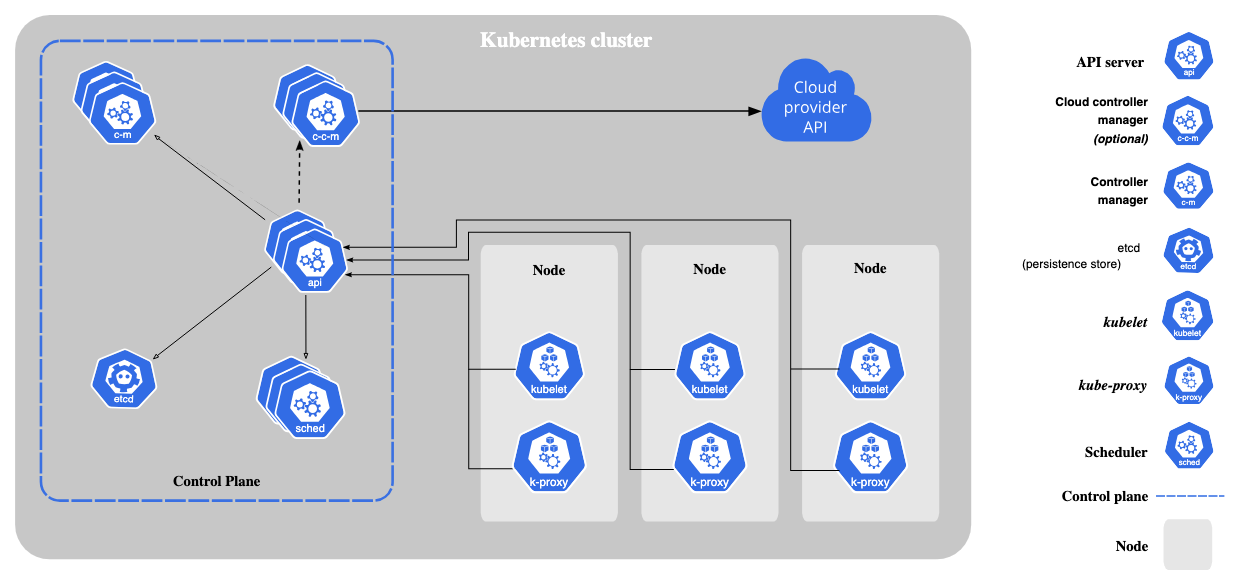
How the Kubernetes Control Plane Works with Worker Nodes
The control plane and worker nodes maintain constant communication. The kubelet, an agent running on each worker node, is the primary point of contact. It receives instructions from the control plane (via the API server) and executes them on the node. The kubelet manages pod lifecycles, ensures containers are running, and reports the node's status back to the control plane. This continuous feedback loop allows the control plane to maintain an accurate view of the cluster's state and make informed decisions. The kubelet's role is critical for managing workloads at the node level. The control plane uses this information to adjust scheduling decisions and ensure the desired state is maintained across the entire cluster.
Worker Node Responsibilities
The worker nodes are the workhorses of your Kubernetes cluster, responsible for running your applications. Think of them as the factory floor where the actual production happens. Each worker node runs several key components:
- kubelet: This agent acts as the primary point of contact between the control plane and the worker node. It receives instructions from the control plane and ensures that containers are running as expected. The kubelet manages the lifecycle of pods, pulling container images, starting and stopping containers, and monitoring their health.
- kube-proxy: This network proxy manages network rules on the node, ensuring that pods can communicate with each other and the outside world. It maintains network connectivity and load balancing for services within the cluster.
- Container Runtime: This is the software responsible for actually running the containers. Popular container runtimes include Docker, containerd, and CRI-O. The container runtime interacts with the operating system kernel to create and manage containers.
Communication Between Control Plane and Worker Nodes
The control plane and worker nodes maintain constant communication to ensure the smooth operation of the cluster. The kubelet, residing on each worker node, serves as the primary communication channel. It receives instructions from the control plane's API server and executes them. These instructions include tasks like deploying new pods, scaling existing deployments, and updating configurations. The kubelet also reports back the status of the node and the pods running on it, providing the control plane with real-time visibility into the cluster's health and resource utilization. This constant feedback loop is essential for the control plane to make informed decisions about scheduling, resource allocation, and maintaining the desired state of the cluster. For a deeper dive into the control plane's components and their interactions, refer to the official Kubernetes documentation.
Kubernetes Add-ons
Kubernetes offers a range of add-ons that extend its core functionality. These add-ons provide essential services for managing and monitoring your cluster. Some commonly used add-ons include:
- DNS (Domain Name System): Provides name resolution within the cluster, allowing pods to easily communicate with each other using service names instead of IP addresses. This simplifies service discovery and makes your applications more resilient to changes in pod deployments. Learn more about DNS in Kubernetes.
- Web UI (Dashboard): Offers a graphical interface for managing and monitoring your cluster. The dashboard provides a visual representation of your resources, allowing you to quickly assess the health of your deployments, view logs, and execute commands. Access the Kubernetes dashboard.
- Monitoring and Logging: These tools collect metrics and logs from your applications and infrastructure, providing insights into resource usage, performance bottlenecks, and potential errors. Robust monitoring and logging are crucial for maintaining the health and stability of your applications. Explore logging options for Kubernetes.
Kubernetes Control Plane Architecture In-Depth
This section explores the architecture of the Kubernetes control plane, detailing its key components and their interactions. Understanding this architecture is fundamental for effectively managing and troubleshooting your Kubernetes clusters.
Key Components of the Kubernetes Control Plane and Their Roles
The control plane is the "brain" of your Kubernetes cluster, responsible for managing its overall state. It consists of several core components, each with a specific role:
- API Server (kube-apiserver): The central communication hub. It exposes the Kubernetes API, the primary interface for interacting with the cluster. All cluster operations transit through the API server.
- Scheduler (kube-scheduler): This component determines where pods (the smallest deployable units in Kubernetes) run on worker nodes. It considers factors like resource requests, node constraints, and data locality to make efficient placement decisions.
- Controller Manager (kube-controller-manager): This component runs controllers that continuously monitor the cluster's state and take corrective actions. For example, if a pod fails, the controller manager ensures a replacement is scheduled.
- etcd: A distributed key-value store holding the cluster's state. All persistent data, including configurations and secrets, resides in etcd. Its reliability and consistency are crucial for cluster stability.
- Cloud Controller Manager (cloud-controller-manager - optional): This component interacts with underlying cloud providers to manage cloud-specific resources, like load balancers and storage volumes. It enables seamless integration with various cloud environments.
kube-apiserver
The kube-apiserver is the central control point for all operations within a Kubernetes cluster. Think of it as the front door—all requests to manage or interact with Kubernetes resources go through it. It validates and authorizes these requests, ensuring that only permitted actions are performed. The API server also plays a crucial role in managing Kubernetes objects, which represent the desired state of your cluster, such as deployments, services, and pods.
The kube-apiserver is designed to be highly available and scalable. It can be deployed as a single instance or in a high-availability configuration with multiple replicas to ensure continuous operation. Its performance is critical for overall cluster responsiveness, as all interactions with the cluster depend on it. For enhanced security, consider using tools like Plural to manage access and authentication to your Kubernetes clusters.
etcd
etcd is the key-value store that holds the persistent state of your Kubernetes cluster. It stores all the critical information about your cluster's configuration, the state of deployed applications, and other essential data. etcd's distributed nature ensures high availability and data consistency, even in the event of node failures. This is crucial for maintaining the stability and reliability of your Kubernetes environment.
Because etcd stores sensitive cluster data, securing it is paramount. Proper access control and encryption are essential to protect your cluster from unauthorized access and data breaches. Regular backups of etcd are also crucial for disaster recovery, allowing you to restore your cluster's state in case of unforeseen events. For simplified management and enhanced security of your etcd clusters, explore platforms like Plural.
kube-scheduler
The kube-scheduler is responsible for deciding where pods (the smallest deployable units in Kubernetes) run on your worker nodes. It acts as a matchmaker, considering factors like resource requests, node constraints (such as taints and tolerations), and data locality to find the best fit for each pod. Efficient scheduling is crucial for optimizing resource utilization and ensuring application performance.
The scheduler's decisions have a direct impact on the overall efficiency and performance of your cluster. By carefully considering resource requirements and node characteristics, the scheduler ensures that workloads are distributed effectively, preventing resource contention and maximizing utilization. Understanding the scheduler's configuration options allows you to fine-tune its behavior to meet the specific needs of your applications. Tools like Plural can further enhance scheduling efficiency by providing a centralized platform for managing and monitoring your Kubernetes deployments.
kube-controller-manager
The kube-controller-manager is a collection of individual controllers that continuously monitor the state of your cluster and take corrective actions to maintain the desired state. These controllers act as automated managers, ensuring that the actual state of your cluster matches the desired state defined in your Kubernetes objects. For example, if a pod fails, the Node Controller detects this and launches a replacement. Other controllers manage services, deployments, and other resources, ensuring their proper operation.
The controller manager is essential for cluster stability and self-healing. By constantly monitoring and adjusting the cluster's state, it ensures that applications remain available and resilient to failures. Understanding the different types of controllers and their functions is crucial for troubleshooting and optimizing your Kubernetes deployments. Platforms like Plural can simplify management and improve the resilience of your controller manager operations by providing centralized control and monitoring.
cloud-controller-manager
The cloud-controller-manager is a component that interacts with your underlying cloud provider. It manages cloud-specific resources, such as load balancers, storage volumes, and network interfaces. This component acts as a bridge between Kubernetes and your cloud infrastructure, allowing you to leverage cloud services seamlessly within your Kubernetes environment. It is typically deployed when running Kubernetes in a cloud environment like Google Kubernetes Engine (GKE), Amazon Elastic Kubernetes Service (EKS), or Azure Kubernetes Service (AKS).
The cloud-controller-manager simplifies the management of cloud resources within your Kubernetes cluster. It automates the provisioning and management of these resources, allowing you to focus on deploying and managing your applications. Understanding the cloud-controller-manager's capabilities is essential for leveraging the full potential of your cloud provider within your Kubernetes deployments. Consider using a platform like Plural to streamline the integration and management of cloud resources with your Kubernetes clusters.
Control Plane Communication Flow
The control plane components continuously communicate to maintain the cluster's desired state. Here's a simplified overview:
- User Interaction: Users interact with the cluster via the API server, submitting requests to manage resources.
- API Server Processing: The API server authenticates and authorizes requests, then persists changes to etcd.
- Controller Manager Monitoring: The controller manager continuously monitors etcd for changes and triggers actions based on its configured controllers.
- Scheduler Placement: When a new pod needs scheduling, the scheduler receives resource availability information from the API server and selects a suitable worker node.
- Worker Node Execution: The kubelet, running on each worker node, receives instructions from the control plane and manages the lifecycle of pods on that node, interacting with the container runtime to start and stop containers.
This continuous communication and reconciliation loop ensures the cluster's actual state converges toward the desired state.
Securing Your Kubernetes Control Plane
A secure control plane is fundamental to a stable and reliable Kubernetes cluster. Without proper security measures, your cluster is vulnerable to threats ranging from unauthorized access to data breaches. This section covers two crucial security aspects: Role-Based Access Control (RBAC) and network policies.
Implementing RBAC in Kubernetes
RBAC is the cornerstone of access management within Kubernetes. It lets you define precisely who can perform specific actions on designated resources within the cluster. This granular control adheres to the principle of least privilege, minimizing potential damage from compromised credentials or accidental misconfigurations. You define roles that encapsulate specific permissions and bind these roles to users or groups. For example, create a role allowing read-only access to deployments in a specific namespace, then bind that role to a monitoring service account.
Kubernetes Network Policies and Encryption
Robust network security is essential for securing your control plane beyond user access. Network policies act as firewalls within your cluster, governing pod communication. By default, all pod communication is unrestricted. Network policies let you specify permitted connections based on labels, namespaces, or IP addresses. This segmentation contains the impact of a compromised pod, preventing lateral movement to other application parts. For example, define a policy allowing traffic to your front-end pods only from the ingress controller, blocking all other connections.
Combining network policies with data encryption in transit and at rest adds another security layer. Encrypting traffic between pods using mTLS ensures confidentiality and integrity. Encrypting secrets and other sensitive data at rest protects against unauthorized access even if the underlying storage is compromised. Consider encrypting your secrets with a key management service for an additional layer of security.
Best Practices for Control Plane Security
Securing your Kubernetes control plane is paramount. A vulnerable control plane can compromise your entire cluster, exposing your applications and data to significant risks. Implementing robust security measures is essential for maintaining a secure and reliable Kubernetes environment. Here are some best practices to strengthen your control plane's security:
Regular Updates and Patching
Regularly updating your Kubernetes cluster to the latest version is crucial for a strong security posture. New releases often include critical security patches, performance improvements, and valuable new features. Staying up-to-date minimizes vulnerabilities and ensures you benefit from the latest security enhancements. Automating this process can significantly reduce operational overhead. Consider managed Kubernetes services like Google Kubernetes Engine (GKE) or Amazon Elastic Kubernetes Service (EKS), which often provide automated update mechanisms, simplifying patching and upgrades.
Secure etcd Access
etcd, the distributed key-value store at the heart of Kubernetes, stores all cluster state information, including sensitive configuration data and secrets. Protecting access to etcd is critical for preventing unauthorized access and potential data breaches. Implement strong access controls, such as role-based access control (RBAC), to restrict access to authorized users and processes only. Encrypting communication with etcd using TLS adds another layer of security, protecting sensitive data in transit. Regular etcd backups are also essential for disaster recovery, enabling you to restore your cluster's state in case of data loss or corruption. For robust secrets management and encryption, explore tools like Vault.
Auditing and Logging
Comprehensive auditing and logging provide invaluable insights into control plane activity. Enable audit logs to track all API server requests, capturing details such as who made the request, the timestamp, and the specific action performed. This detailed record is crucial for identifying suspicious activity, investigating security incidents, and ensuring compliance. Configure robust logging for all control plane components to capture errors, warnings, and other relevant events. Centralized logging solutions, such as Elasticsearch, Logstash, and Kibana (ELK) or Splunk, can help aggregate and analyze logs from various sources, providing a comprehensive view of your cluster's health and security posture. Consider using Plural’s platform to streamline these processes and gain deeper visibility into your Kubernetes deployments.
High Availability for the Kubernetes Control Plane
High availability and redundancy are crucial for mission-critical Kubernetes deployments. If your control plane fails, your entire cluster goes down with it. This section covers key strategies for ensuring your control plane can withstand failures and maintain continuous operation.
Multi-Master Kubernetes Setups and Load Balancing
Running a single master node creates a single point of failure. Production Kubernetes deployments should always use multiple master nodes. This setup, often called a multi-master or high-availability control plane, distributes the workload across several nodes. If one master becomes unavailable, the others continue operating without interruption. Distributing the load also improves performance, especially during periods of high traffic. A load balancer in front of the master nodes distributes incoming traffic evenly, further enhancing availability and preventing overload. Platforms like Plural's architecture, with its separation of the management cluster and agents within each workload cluster, enhances this model, providing additional scalability and security.

Control Plane Backup and Recovery
Redundancy within the control plane is essential but insufficient on its own. You also need a robust backup and recovery plan. This plan should cover all critical control plane components, including etcd (the key-value store for cluster data), configuration files, and any other relevant state. Regular backups are crucial. The frequency depends on your specific needs and recovery point objectives (RPO). Test your recovery procedures regularly. A backup is useless if you can't restore it effectively. Practice restoring your cluster from backups to validate your procedures and ensure a quick recovery from failures.
Monitoring and Troubleshooting Your Kubernetes Control Plane
Effective Kubernetes management requires comprehensive monitoring and swift troubleshooting of its control plane. This involves tracking key metrics, using diagnostic tools, and understanding common issues and their solutions.
Essential Metrics and Diagnostics for Kubernetes
Monitoring the Kubernetes control plane components—the API server, controller manager, scheduler, etcd—is crucial for maintaining resource efficiency and overall cluster health. Track API server request latency to identify potential bottlenecks. High latency can indicate an overloaded API server or network issues. Monitor etcd performance metrics, such as request latency and database size, to ensure its responsiveness. Etcd stores critical cluster state information, so its performance directly impacts overall cluster stability. Keep an eye on controller manager metrics to understand the performance of controllers responsible for managing various Kubernetes resources. Visualizing these metrics with tools like Prometheus and Grafana provides valuable insights into the control plane's operational state.
Common Kubernetes Issues and How to Solve Them
Troubleshooting control plane issues can be complex. A common bottleneck is etcd database performance. If not properly scaled and monitored, etcd can struggle to keep up with the demands of a busy cluster. Consider using dedicated etcd monitoring tools to gain deeper insights into its performance and identify potential issues early on. Regularly check the logs of core control plane components—kube-apiserver, kube-controller-manager, and kube-scheduler—for errors. These logs often provide valuable clues for diagnosing and resolving issues. Dedicated logging and monitoring tools can significantly streamline the troubleshooting process. For example, consider using a centralized logging solution like Fluentd to aggregate logs from all control plane components, making it easier to correlate events and identify the root cause of problems. For persistent logging, integrate Fluentd with a solution like Elasticsearch and Kibana for long-term storage, analysis, and visualization of your log data.
Managing and Updating the Kubernetes Control Plane
Managing and updating your Kubernetes control plane is crucial for security and efficiency. This involves not only keeping core components up-to-date but also implementing robust processes for change management. A well-maintained control plane ensures the reliability and security of your entire Kubernetes cluster.
Kubernetes Update Strategies and Patching
Regular updates are essential to patch vulnerabilities and access new features. Aim for a balance between staying current and minimizing disruption. A rolling update strategy, updating control plane nodes one by one, is often preferred to maintain service availability and minimize downtime. Before any update, back up your etcd database, which stores critical cluster data, to ensure you can restore your cluster if an update fails. For less critical patches, a canary deployment—updating a small subset of nodes first—allows you to observe the impact before a full rollout. Thorough testing in a staging environment is always recommended before updating your production cluster.
Consider leveraging a tool like Plural to efficiently manage updates across your Kubernetes fleet. This solution streamlines cluster upgrades through automated workflows that perform compatibility checks and proactively manage dependencies, ultimately enabling seamless and scalable operations across your entire infrastructure.

Documentation and Change Control for Kubernetes
Clear documentation is fundamental for effective control plane management. Maintain comprehensive documentation of your control plane configuration, including component versions, network settings, and security policies. This documentation acts as a single source of truth and simplifies troubleshooting. A well-defined change control process is equally important. Before any changes, document the proposed modification, its potential impact, and the rollback plan. This ensures changes are reviewed and approved, reducing the risk of unintended consequences. Tools like GitOps can automate and track infrastructure changes, further streamlining the change control process. Combining robust documentation with a structured change control process creates a more stable and manageable Kubernetes environment.
Creating and Managing Kubernetes Clusters
Creating a Kubernetes cluster can range from simple to quite complex, depending on your needs and environment. Let's explore a few common approaches.
Using Cloud Providers (EKS, AKS, GKE)
Managed Kubernetes services like Amazon Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), and Google Kubernetes Engine (GKE) offer a streamlined way to deploy and manage clusters. These services handle much of the underlying infrastructure, letting you focus on your applications. Cloud providers offer their own command-line tools for interacting with these services. For example, you can create and manage EKS clusters using the AWS CLI, GKE clusters using the gcloud CLI, and AKS clusters using the Azure CLI. This simplifies cluster lifecycle management, from initial creation to scaling and upgrades. For a deeper dive into using cloud providers for Kubernetes, check out this article on setting up Kubernetes on various cloud platforms.
Manual Installation with kubeadm
For more control over your cluster setup, kubeadm is a powerful tool. Kubeadm automates the process of bootstrapping a best-practices Kubernetes cluster. It handles the complex configuration of the control plane components and worker nodes, simplifying the installation process. While this approach requires more manual configuration than managed services, it offers greater flexibility and control, especially for on-premises deployments or customized environments. This guide to deploying virtual Kubernetes clusters provides more context on manual installation.
Lightweight Tools (Kind, Minikube, k3s, MicroK8s)
For local development and testing, lightweight Kubernetes distributions like Kind, Minikube, k3s, and MicroK8s are excellent choices. These tools provide a simplified Kubernetes experience ideal for experimenting, testing deployments, or running local development environments without the overhead of a full-blown cluster. They are resource-efficient and easy to set up, making them perfect for developers who want to get started quickly. This comparison of Kubernetes cloud providers offers further insights into lightweight tools.
Helm: Simplifying Deployments
Helm acts as a package manager for Kubernetes, simplifying the deployment and management of applications. With Helm, you define your application's deployment using Helm charts, which are templates that describe the desired state of your Kubernetes resources. This allows you to package and deploy even complex applications with ease, managing dependencies and configurations efficiently. Helm also simplifies upgrades and rollbacks, making it a valuable tool for managing the application lifecycle within your Kubernetes cluster. For more on Helm and deployments, revisit the guide to deploying virtual Kubernetes clusters mentioned earlier.
Scaling Your Control Plane
Scaling your Kubernetes control plane is essential for handling increased workloads and ensuring high availability.
Scaling to 5,000 Nodes
Kubernetes is designed to scale to thousands of nodes. As your cluster grows, ensure your control plane has sufficient resources to manage the increased workload. This might involve increasing the resources allocated to control plane components like the API server, scheduler, and controller manager. Proper configuration and resource allocation are key to maintaining performance as you scale. Consider using etcd performance tuning and monitoring to ensure its responsiveness under heavy load. The article on setting up Kubernetes on various cloud platforms also discusses scaling considerations.
Persistent Storage with Persistent Volumes
Persistent Volumes (PVs) provide a way to manage storage independently of the lifecycle of individual pods. This is crucial for stateful applications that require data persistence. PVs abstract the underlying storage infrastructure, allowing you to define storage requirements without worrying about the specifics of the storage provider. This simplifies storage management and ensures data persistence across pod restarts and scaling operations. Refer back to the guide to deploying virtual Kubernetes clusters for more details on persistent storage.
Container Networking in Kubernetes
Understanding Kubernetes networking is crucial for building and deploying applications effectively.
Understanding Pod Networking
Kubernetes provides a flat network structure where each pod has its own IP address. This allows pods to communicate directly with each other, regardless of which node they are running on. This simplifies application development and deployment, as you don't need to manage complex network configurations within your pods. The Kubernetes network model ensures seamless communication between pods across the cluster. The article on setting up Kubernetes on various cloud platforms provides a good overview of pod networking.
Network Policies for Enhanced Security
Network policies act as firewalls within your Kubernetes cluster, controlling traffic flow between pods. By default, all pod communication is allowed. Network policies enable you to define granular rules based on labels, namespaces, or IP addresses, restricting traffic and enhancing security. This segmentation helps prevent unauthorized access and limits the impact of security breaches by isolating compromised pods. For example, you can create a network policy that only allows traffic to your backend pods from your frontend pods, blocking all other connections. This adds a crucial layer of security to your Kubernetes deployments. For a more in-depth look at network policies, see the official Kubernetes documentation.
Solving Kubernetes Operational Challenges
Kubernetes simplifies container orchestration, but managing it at scale introduces complexities. Troubleshooting distributed systems, securing a constantly evolving environment, and maintaining infrastructure across multiple clusters require specialized expertise and substantial resources.
Gartner’s Best Practices for Kubernetes Cluster Architecture
Gartner, a leading research and advisory company, offers valuable insights into best practices for Kubernetes cluster architecture. These best practices emphasize a secure, scalable, and resilient approach to Kubernetes deployments, focusing on key areas like control plane design, network security, and resource management.
A key recommendation revolves around the control plane, the central nervous system of your Kubernetes cluster. Gartner stresses the importance of a highly available control plane to ensure business continuity. This involves deploying multiple master nodes and leveraging load balancing to distribute traffic and prevent single points of failure. This aligns with the principle of redundancy, ensuring that the loss of a single master node doesn't cripple the entire cluster. For more in-depth information on control plane architecture, refer to Plural's guide on Kubernetes Control Plane Architecture.
Network security is another critical area. Network policies are essential for controlling traffic flow within the cluster, acting as firewalls between pods and namespaces. By implementing strict network policies, you can limit the “blast radius” of security breaches, preventing unauthorized access to sensitive applications and data. Gartner also recommends encrypting traffic between pods and encrypting data at rest to further enhance security.
Resource management is crucial for optimizing Kubernetes performance and cost-efficiency. Gartner advises implementing resource quotas and limit ranges to prevent resource starvation and ensure fair allocation across different workloads. This prevents individual applications from monopolizing cluster resources and guarantees predictable performance. Gartner also emphasizes the importance of monitoring resource utilization to identify potential bottlenecks and optimize resource allocation.
Finally, Gartner underscores the importance of robust documentation and change control processes. Maintaining up-to-date documentation of your cluster configuration, security policies, and operational procedures simplifies troubleshooting and ensures smooth operations. Implementing a structured change control process, including peer reviews and automated testing, minimizes the risk of errors during updates and configuration changes.
Reduce Kubernetes Complexity and Overhead
Kubernetes itself is a complex system. Troubleshooting issues, whether related to networking, resource allocation, or application deployments, can be time-consuming and require deep Kubernetes knowledge. This operational overhead impacts engineering teams who must dedicate significant time to maintenance rather than feature development. As your organization scales its Kubernetes footprint, managing multiple clusters, diverse workloads, and the underlying infrastructure further amplifies this complexity. This can lead to slower release cycles and increased operational costs. Providing a consistent workflow for deployments, dashboarding, and infrastructure management becomes critical for efficient operations. For example, managing RBAC across a large fleet can be cumbersome without a centralized system such as Plural.
Plural Simplifies Kubernetes Management
Managing Kubernetes at scale can feel like juggling chainsaws. You’re dealing with complex deployments, intricate security policies, and the ever-present challenge of keeping everything running smoothly across your entire fleet. Plural simplifies these complexities by providing a unified platform to manage all aspects of your Kubernetes deployments, from application deployments and infrastructure management to security and upgrades.
Our platform streamlines upgrades, ensuring your clusters are always up-to-date with the latest security patches and features. We automate workflows, freeing your team from tedious manual tasks, like patching and scaling, and reducing the risk of human error. This automation extends to infrastructure management, allowing you to easily provision and manage resources across all your clusters through a streamlined, GitOps-driven approach.
With Plural, you gain enhanced visibility into your Kubernetes environment. Our secure dashboards provide real-time insights into cluster health, resource utilization, and application performance. This centralized view simplifies troubleshooting and empowers you to proactively identify and address potential issues before they impact your users. And because security is paramount, Plural integrates seamlessly with existing RBAC systems, giving you granular control over access and permissions across your entire Kubernetes fleet. This centralized RBAC management simplifies compliance and ensures that your clusters adhere to the strictest security standards.
Strategies for Common Kubernetes Hurdles
To mitigate these challenges, adopt strategies that streamline Kubernetes management and reduce operational overhead. Implementing robust monitoring and troubleshooting tools helps identify and resolve issues quickly. Centralized logging and metrics provide valuable insights into cluster health and performance, enabling proactive identification of potential problems. Consider a GitOps approach for managing Kubernetes configurations, ensuring consistency across environments, and simplifying rollbacks. Automating routine tasks, such as deployments and scaling, frees up engineering teams to focus on higher-value activities. A well-defined disaster recovery plan is crucial for minimizing downtime and data loss in case of unforeseen events.
Finally, invest in training and development to empower your team with the necessary Kubernetes expertise. Addressing the knowledge gap through targeted training programs and knowledge-sharing initiatives improves operational efficiency and reduces the risk of errors. Tools like Plural offer a unified platform for managing Kubernetes deployments, infrastructure, and access control, significantly reducing operational complexity and improving overall efficiency.

The Future of the Kubernetes Control Plane
As Kubernetes matures, its control plane is evolving beyond simply managing containers. New architectures and management paradigms are emerging, promising greater scalability, flexibility, and operational efficiency. To prepare for these advancements, consider the following:
- High Availability and Scalability: Next-generation control planes will need to handle increasing workloads and maintain high availability. Services like DigitalOcean Kubernetes already offer HA control planes with robust SLAs, setting a precedent for future expectations. This requires careful consideration of multi-master setups, load balancing, and automated failover mechanisms.
- Simplified Management: As control planes become more powerful, managing their complexity becomes crucial. Tools like Plural simplify Kubernetes management by providing a single, unified interface for controlling your entire fleet. This streamlines operations reduces manual intervention and empowers teams to manage Kubernetes effectively without requiring deep specialized knowledge.
- Security and Compliance: With expanded capabilities comes increased responsibility for security. Next-generation control planes will demand robust security measures, including advanced RBAC, network policies, and encryption. Ensuring compliance with industry regulations and security best practices will be paramount.
Related Articles
- Kubernetes Mastery: DevOps Essential Guide
- Deep Dive into Kubernetes Components
- Kubernetes API: Your Guide to Cluster Management
- Top tips for Kubernetes security and compliance
- Kubernetes Cluster Management: A Practical Guide
Unified Cloud Orchestration for Kubernetes
Manage Kubernetes at scale through a single, enterprise-ready platform.
Frequently Asked Questions
What are the core components of the Kubernetes control plane, and what are their responsibilities?
The Kubernetes control plane consists of the API server, scheduler, controller manager, etcd, and optionally the cloud controller manager. The API server is the central communication hub, handling all requests. The scheduler determines where pods run. The controller manager maintains the desired cluster state. etcd stores cluster data and the cloud controller manager interacts with cloud providers.
How can I secure my Kubernetes control plane against unauthorized access and threats?
Implement Role-Based Access Control (RBAC) to define granular permissions for users and services. Use network policies to restrict traffic flow between pods, limiting the impact of potential breaches. Encrypt sensitive data both in transit and at rest to protect against unauthorized access.
What strategies can I use to ensure high availability and prevent downtime for my control plane?
Use multiple master nodes in a high-availability setup. This distributes the workload and provides redundancy. If one node fails, the others continue operating. Implement a robust backup and recovery plan for your etcd data and control plane configuration. Regularly test your recovery procedures to ensure they function correctly.
How can I effectively monitor the health and performance of my Kubernetes control plane?
Monitor key metrics like API server request latency, etcd performance, and controller manager health. Use tools like Prometheus and Grafana to collect and visualize these metrics. Regularly check control plane logs for errors and warnings. Set up alerts for critical events to enable proactive responses.
What are some best practices for optimizing the performance and efficiency of my control plane?
Scale your control plane by adding more master nodes as your cluster grows. Allocate sufficient resources (CPU, memory, and disk) to control plane components. Keep your Kubernetes version up-to-date to benefit from performance improvements and bug fixes. Implement readiness and liveness probes to ensure control plane components are functioning correctly.

Newsletter
Join the newsletter to receive the latest updates in your inbox.








{kind=link}