
Scaling GitOps: A Deep Dive into the GitOps Engine
Learn how Plural optimized its GitOps engine for scalability, addressing challenges like resource consumption and latency in Kubernetes environments.
GitOps uses Git as the source of truth for your infrastructure. A GitOps engine continuously compares your Kubernetes API against the YAML defined in Git. This constant reconciliation loop is key to Plural's Fleet Management solution. It addresses two crucial concerns: managing infrastructure and ensuring the desired state.
- Scalable configuration of large sets of clusters, since Git can effectively publish-subscribe configuration to any subset of your fleet via a few CRDs we’ve crafted, it provides a perfect developer experience to manage fleets as long as the system is optimized for large cluster counts.
- An efficient bulk resource application framework for more complicated infrastructure provisioning and automation, like creating a tenanted fleet with a single PR, like in this demo. Just define a large set of declarative resources in a single folder, create a Plural service against the folder, and let the system do everything from terraform execution, to syncing Kubernetes manifests and setting up RBAC access to various resources.
In brief, since this isn’t a blog post about Plural itself, the architecture involves a central management hub, and an on-cluster agent that receives tarballed resource manifests to apply in a constant reconciliation loop. This architecture does a great job of distributing work across clusters since resource application is cluster-local and thus shared. We have noticed, however, that the agent became a bottleneck on very large clusters and knew we needed to optimize.
That said, we constantly maintain an internal design constraint ensuring our agent is as lightweight as possible, since if you have a 1-1 relationship between agent and cluster, it should be functionally a background concern to not trade the problem of cluster management for agent management (and for what its worth, this is why we chose to make a custom implementation since we wanted full control of the source code to optimize it as closely as possible).
Unified Cloud Orchestration for Kubernetes
Manage Kubernetes at scale through a single, enterprise-ready platform.
What Problem Are We Solving?
The core issue derives from the reconciliation loop approach to resource application. While the reconciliation loop is a powerful mechanism for ensuring that the desired state of a system matches the actual state, it does have some drawbacks and challenges:
- Resource Consumption: Constantly applying changes can lead to increased load on the Kubernetes API server, especially in large and dynamic environments. If policy management tools like OPA Gatekeeper are present which heavily leverage admission controllers, this can propagate down to node resource overutilization as well.
- Latency: There can be a delay between detecting a state change and its reconciliation, leading to temporary inconsistencies. This is aggravated by the fact that you might need to Server-Side Apply each object, which even with parallelism consumes a lot of time, and then watch for status updates, consuming even more wall-clock time.
- Race Conditions: No matter what, this is going to be heavily parallelized. Each object is applied in a fixed goroutine pool, and naively implemented caching approaches will be tormented with races and other concurrency bugs as a result.
Key Takeaways
- Resource caching significantly improves GitOps performance: By caching resource state, Plural's agent minimizes Kubernetes API server load and drastically reduces reconciliation times, leading to faster deployments and improved resource utilization.
- The GitOps Engine provides a robust and scalable foundation: Building upon the GitOps Engine enables Plural to focus on platform-specific enhancements, such as security and multi-cluster management, without reinventing core GitOps functionality.
- Understanding the Kubernetes ecosystem is essential for optimized GitOps: Consider the performance implications of admission controllers and CRD lifecycles when designing and implementing GitOps workflows for large-scale Kubernetes deployments.
The Challenges of Scaling GitOps
Scaling GitOps effectively presents several challenges we need to address to ensure optimal performance and reliability. One of the primary concerns is resource consumption. The reconciliation loop, while powerful, can lead to increased load on the Kubernetes API server, particularly in large and dynamic environments. This increased load can worsen when policy management tools, such as OPA Gatekeeper, are in use. Because they rely heavily on admission controllers, this can lead to node resource overutilization.
Another significant challenge is latency. Delays can occur between detecting a state change and its reconciliation, causing temporary inconsistencies. Performing Server-Side Apply for each object further complicates this issue. Even with parallelism, this operation consumes considerable time and resources while waiting for status updates. At Plural, we encountered these latency challenges firsthand as we scaled our GitOps platform to manage increasingly large and complex Kubernetes deployments. Our experience managing multi-tenant clusters highlighted the importance of optimizing the reconciliation loop for minimal latency.
Finally, race conditions pose a considerable risk in heavily parallelized environments. Each object is applied in a fixed goroutine pool. If caching approaches are not implemented carefully, they can lead to races and other concurrency bugs, complicating the reconciliation process. These challenges were central to our focus as we developed Plural. We prioritized building a system that could handle the complexities of parallel processing while mitigating the risks of race conditions. Our agent-based architecture, with its focus on distributing workload and optimizing resource application, directly addresses these scaling challenges.
Why the Legacy Implementation Struggled
We originally adopted cli-utils as the library of choice for bulk resource application. It is a relatively lightweight project supported by a Kubernetes SIG and it gave us core features like client-side resource schema validation, parallelizing resource application across multiple goroutines, easy configuration for basic apply settings, filtering logic, and status watching logic. Gitlab’s GitOps agent leverages the library as well as ours, and we believe Anthos’ Config Sync also uses it under the covers. Internally, it leverages Kubernetes Server-Side Apply, which really deserves its own discussion.
Server-Side Apply (SSA) in Kubernetes is a powerful feature that essentially updates only the parts of the resource that have changed by comparing an object with the live state on the Kubernetes API server. This can mean SSAs are relatively lightweight API calls, however, they still pass through all Kubernetes admission webhooks, and there is inherent latency in making any network call to the API server. Multiply that across hundreds of resources in a cluster, reconciled continuously, and it can still put meaningful pressure on your cluster and drag down the responsiveness of our agent.
The cli-utils implementation had several substantial drawbacks though. First, there was no way to track the state between applies (it was conceptually built around making it easier to make one-off CLIs similar to kubectl). We would need that if we wanted to deduplicate unnecessary applies between reconciliations. Secondly, its status-watching logic is naive and only suitable for a CLI use case. In particular, it works like this:
- for every group, kind, and namespace applied in bulk, issue a watch for that tuple on demand
- wait for either a timeout to finish or the resource to converge on a ready state, and close the watch.
This is fine in a CLI use case since the process is short-lived and you’d need to on-demand watch anyway, but in a persistent, constantly reconciling agent, it causes needless network call overhead. A better strategy is to record the GVKs that have been historically applied, and keep a fixed list of watch streams open for each of them and then use those streams to gather status.
The second key insight was that if we’re capturing the watch streams, we could devise a simple, resource-efficient caching strategy to deduplicate unneeded applies based on the events we see incoming.
Scaling GitOps: Our Solution
We've built our streamlined cache based on SHA hashes. For any unstructured Kubernetes object received in a watch stream, we compute a few SHAs based on:
- object metadata (only name, namespace, labels, annotations, deletion timestamp)
- all other top-level fields except status which is a reserved field in kubernetes unrelated to applies
In full, the cache entry looks like:
// ResourceCacheEntry contains the latest SHAs for a single resource from multiple stages
// as well as the last-seen status of the resource.
type ResourceCacheEntry struct {
// manifestSHA is SHA of the last seen resource manifest from the Git repository.
manifestSHA *string
// applySHA is SHA of the resource post-server-side apply.
// Taking only metadata w/ name, namespace, annotations and labels and non-status non-metadata fields.
applySHA *string
// serverSHA is SHA from a watch of the resource, using the same pruning function as applySHA.
serverSHA *string
// status is a simplified Console structure containing last seen status of cache resource.
status *console.ComponentAttributes
}
Plural and the GitOps Engine
How Plural Leverages the GitOps Engine for Scalability
Plural leverages the GitOps Engine, a core library also used by Argo CD, to provide a robust and scalable GitOps experience. This engine handles essential GitOps functions, including managing Kubernetes resources, reconciling changes, and planning deployments. It also manages access to Git repositories and generates deployment manifests, freeing developers to focus on application logic rather than infrastructure management. By building on this established foundation, Plural ensures efficient synchronization between Git and your Kubernetes clusters, regardless of scale. This offers a significant advantage for platform engineering teams managing complex deployments.
The GitOps Engine’s ability to handle resource diffs and customizable health assessments is crucial for Plural’s scalability. These features, highlighted in the Argo CD roadmap, allow Plural to efficiently manage large numbers of resources across multiple clusters. By only applying necessary changes, Plural minimizes the load on the Kubernetes API server and reduces the risk of inconsistencies. This targeted approach is particularly important in dynamic environments where frequent updates are common and system stability is paramount.
Benefits of Using Plural for GitOps
Plural enhances core GitOps principles to provide a streamlined and scalable solution for managing Kubernetes deployments. Similar to tools like Red Hat OpenShift GitOps, Plural uses Git as a single source of truth, improving workflow, security, reliability, and consistency. This approach simplifies auditing and rollback procedures, contributing to a more secure and manageable infrastructure. However, Plural goes beyond basic GitOps functionality by offering a comprehensive platform for managing entire fleets of Kubernetes clusters. This makes it particularly well-suited for organizations with complex, multi-cluster environments.
One of the key benefits of using Plural for GitOps is its ability to handle the scalable configuration of large sets of clusters. By leveraging Git's distributed nature, Plural can efficiently distribute configuration changes to any subset of your fleet. This eliminates the need for manual intervention and reduces the risk of errors, freeing up platform teams for more strategic work. Furthermore, Plural provides an efficient bulk resource application framework for complex infrastructure provisioning and automation. This allows you to manage large-scale deployments with ease, simplifying tasks like creating tenanted fleets with a single pull request, as demonstrated in this demo. This streamlines the process of managing even the most complex deployments, saving valuable time and resources.
When to Apply a Resource with the GitOps Engine
A resource can be applied if either of the following conditions is met:
applySHA≠serverSHA- The SHA of a Git manifest being reconciled ≠ last calculated
manifestSHA
Design Decisions Behind the GitOps Engine
- Git Manifest SHA Divergence - if the SHA of a Git manifest diverges, it indicates that the Git upstream has changed. In such cases, the resource must be modified regardless of other factors.
- Resource Drift - if there is no divergence in the Git manifest SHA, any drift in the resource would be due to reconfiguration by another client. This drift would trigger a watch event and cause a change in
serverSHA. The change should then be reconciled back in the next loop of the agent.
By following this logic, we ensure that resources are only modified when necessary, maintaining consistency and alignment with the upstream Git repository and handling any external reconfigurations efficiently.
There were two main things we got out of this:
- Great memory efficiency - this struct is highly compressed, versus just caching the entire object from the Kubernetes API, allowing us to handle very large cluster sizes with memory footprints under 200Mi.
- Consistency - Kubernetes watches have strong consistency guarantees deriving from etcd’s raft implementation. If the watch is managed properly, we can ensure any update to a given resource ultimately populates the cache, and thus drive our hit rates well over >90% at a steady state (with the resulting misses due to multiple services contesting a common resource).
Key Packages and Their Roles
The Argo CD team created a reusable Go library called the GitOps Engine. This library handles core GitOps functionality, making it easier to build GitOps operators. Key features include managing a cache of Kubernetes resources, reconciling resources (keeping them in sync), planning synchronization steps, accessing Git repositories, and generating Kubernetes manifests. Plural leverages this library, enabling us to focus on scalability and security enhancements rather than rebuilding these core features.
Addressing Security Concerns (GO-2025-3437)
While the GitOps Engine provides a robust foundation, addressing security vulnerabilities is paramount. One such vulnerability, identified as GO-2025-3437 (CVE-2022-24449), involved un-scrubbed secret values appearing in patch errors. This vulnerability, present in versions prior to 0.7.3, had the potential to expose sensitive information. Plural mitigates this risk by exclusively using patched versions of the GitOps Engine. We actively monitor for and address any new vulnerabilities to maintain a secure GitOps workflow.
Benchmarking the GitOps Engine
The below images show the differences between our deployment-operator with cache enabled and disabled. The first one shows cache-related metrics as well as general resource consumption. The second one shows the measured execution time of the service reconcile loop with the distinction to different stages of the reconciliation process. In general, it performs these steps:
- Initialize - get Service object either from cache or API.
- Process Manifests - fetch the manifests tarball from the API, untar, and template them.
- Apply - run the
cli-utilsapply.
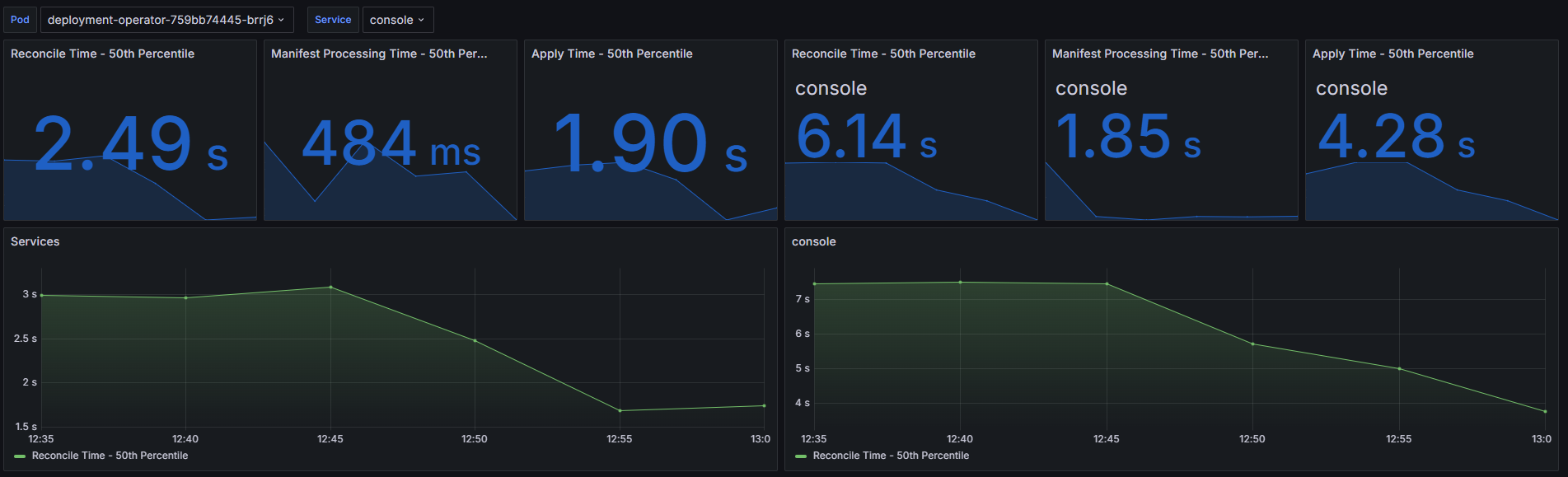
You can see both the 50th percentile reconcile times of all services across the cluster and the same times measured for the console service. I have specifically selected console service as it is one of our biggest services that has to process a big number of CRDs during the apply. It has 56 resources that would normally need to be reapplied during every reconcile.
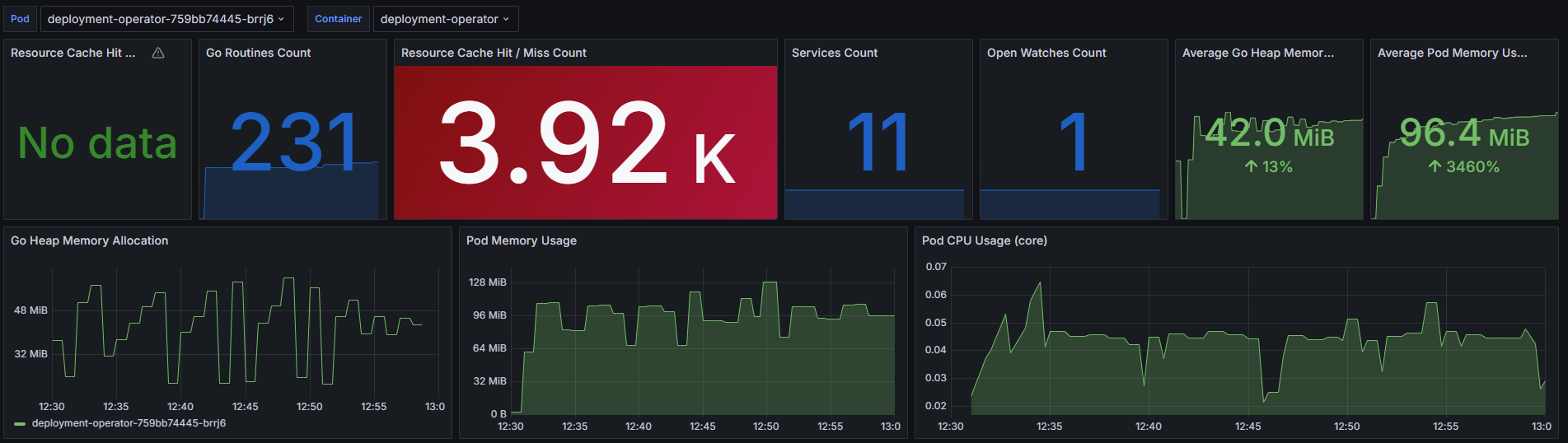
Cache Disabled: Benchmark Results
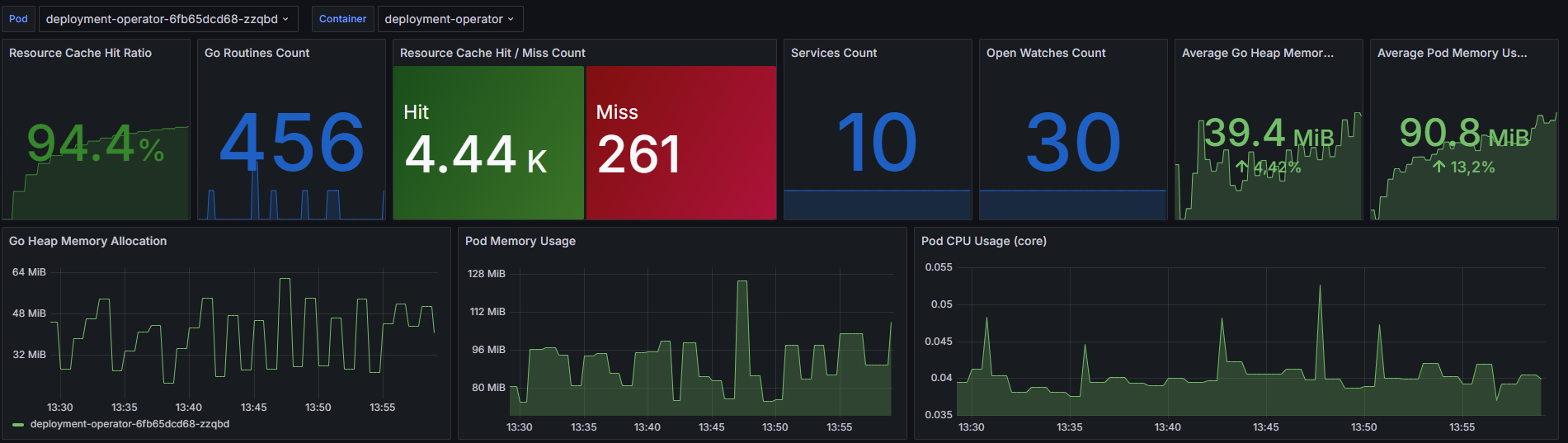
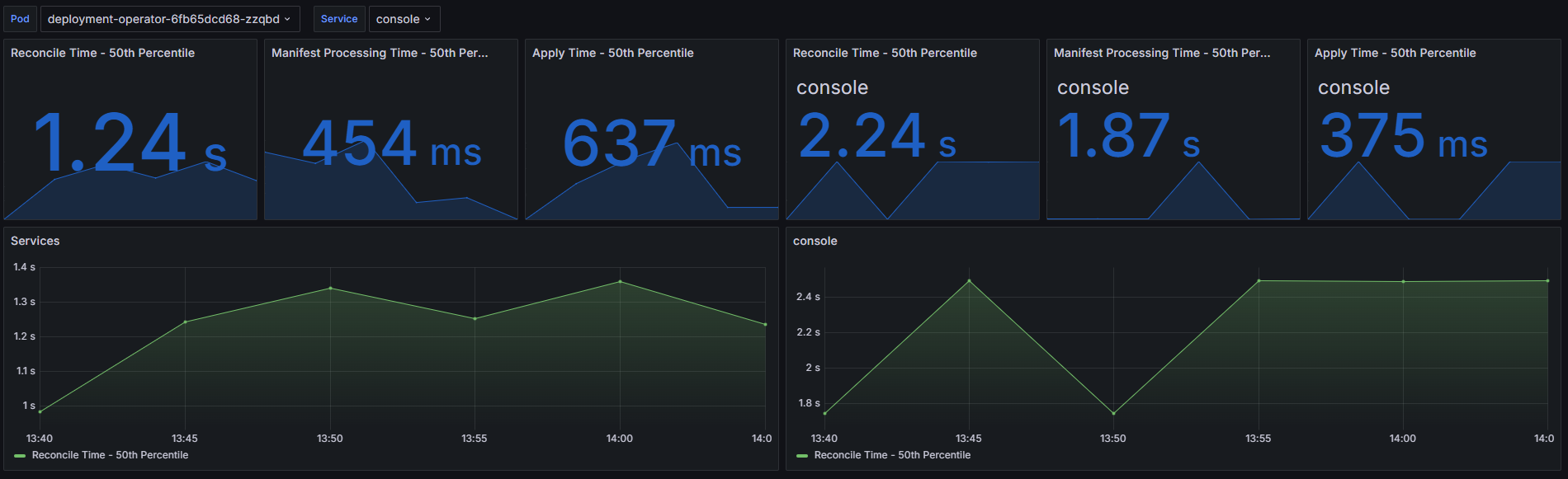
Cache Enabled: Benchmark Results
Performance Improvements with the GitOps Engine
As seen based on the above images enabling resource cache in the deployment operator provides notable improvements across various performance metrics:
Performance Improvement
- Reconcile Time - the average reconcile time is halved, dropping from 2.49 seconds to 1.24 seconds, significantly speeding up the reconciliation process.
- Apply Time - the average apply time is reduced by more than half, from 1.9 seconds to 637 milliseconds, enhancing the speed of applying changes. A lot of this residual latency is just setting up the
cli-utilsapplier, validating the namespace is in place, and setting up the go client’s features like schema mapper. We can likely optimize that away too, just still need to work on it.
Console Service Optimization
- Reconcile Time - for the console service, the average reconcile time decreases from 6.14 seconds to 2.24 seconds, a substantial improvement.
- Apply Time - the average apply time for the console service drops from 4.28 seconds to 375 milliseconds, ensuring faster application of configurations.
Resource Cache Effectiveness
- Hit Ratio - a high resource cache hit ratio of 94.4% indicates that the majority of resource requests are being efficiently served from the cache, reducing the need for repeated data fetching and processing.
Lessons Learned Scaling GitOps within Kubernetes
One of the more interesting things we discovered in this journey is how the sprawling nature of the Kubernetes ecosystem heavily amplifies API server load. Many open source controllers, like OPA Gatekeeper, Istio, etc, heavily leverage admission controllers, which get called per apply. If you have automation that applies frequently, like a CD tool, or really any theoretical controller, it implicitly can propagate load on cluster in unexpected, unintuitive ways due to those transitive dependencies.
The second is the CRD lifecycle. There is a known issue where the Kubernetes go client’s API discovery cache heavily throttles clients when CRDs change. Any continuous deployment implementation, or really any tooling that touches CRDs, can trigger this bug if it's not delicate. We had solved this directly with a cli-utils apply filter, but the caching approach we introduced provided a more general framework that also sidestepped client throttling bugs that could have occurred.
The last is the complexity of managing the Kubernetes Watch API. We needed to build a customStatusWatcher that we could use as a replacement for the cli-utils default watcher and as a base for our global resource cache. We have done several optimizations there, but the main one was a replacement of shared informers with a thin wrapper around the dynamic client that is responsible for doing an initial list call, feeding it into the event channel, starting a watch from extracted resourceVersion and in case of any error during watch, restarting it while keeping last seen resourceVersion . This ensures that no events are missed between the list and watch, and during restarts i.e. if the API server drops a watch after some time. Another benefit is improved memory usage since the dynamic client doesn’t provide a built-in caching mechanism and we decided to take advantage of this and build our own cache.
Thanks to all this we can ensure that there is only a single watch open for every unique resource type found in the cli-utils inventory, but also reuse the same StatusWatcher while configuring the cli-utils applier.
Credits to Łukasz Zajączkowski, Michael Guarino, and Marcin Maciaszczyk for the joint effort in the design, implementation and creation of this blog post.
The Future of GitOps and the GitOps Engine
The evolution of GitOps tooling is intrinsically linked to the growth and maturation of projects like Argo CD and its underlying GitOps Engine. This engine, a core component of Argo CD, provides the fundamental logic for Git-based continuous delivery, making it a critical piece of the GitOps puzzle. Understanding its trajectory helps us anticipate the future of GitOps itself.
Argo CD Roadmap and its Implications
The Argo CD roadmap prioritizes enhancing functionality and user experience for Kubernetes GitOps. This includes ongoing bug fixes and performance improvements, crucial for maintaining a stable and efficient platform. Beyond these core elements, the roadmap highlights feature enhancements like customizable health assessments, allowing for more nuanced and application-specific health checks. Improvements to resource diffing within the argoproj/gitops-engine library are also planned, promising more precise and informative comparisons between desired and actual cluster states. These advancements directly impact the efficiency and reliability of GitOps deployments. For instance, more robust diffing capabilities could enable faster identification of drift and more targeted remediation, reducing downtime and improving overall system stability.
Community Involvement and Contributions
The open-source nature of the argoproj/gitops-engine project fosters a vibrant community, encouraging contributions and collaboration. The project maintainers actively welcome code contributions, feedback on existing features, new ideas, and the sharing of diverse use cases. This collaborative environment is essential for driving innovation and ensuring the engine remains adaptable to evolving Kubernetes landscapes. For example, community feedback can help prioritize features and identify areas for improvement, leading to a more robust and user-friendly tool. The project's active Slack channel (#argo-cd-contributors on CNCF Slack) provides a direct line of communication with the development team and other community members, further facilitating engagement and knowledge sharing. With over 1.7k stars and 276 forks on GitHub, and usage in over 500 projects, the project clearly demonstrates significant community interest and adoption, solidifying its position as a key player in the GitOps ecosystem. This strong community backing not only contributes to the project's ongoing development but also provides valuable support and resources for users.
Related Article
Unified Cloud Orchestration for Kubernetes
Manage Kubernetes at scale through a single, enterprise-ready platform.
Frequently Asked Questions
Why isn't Plural using Argo CD directly if it's built on the GitOps Engine?
Plural leverages the GitOps Engine as a library to manage core GitOps functionality, giving us fine-grained control over performance and security. Directly embedding Argo CD introduces additional complexity and overhead that isn't necessary for Plural's agent-based architecture. This approach allows us to tailor the GitOps experience specifically for fleet management at scale, optimizing for performance in large, dynamic environments.
How does Plural's caching mechanism improve performance?
Our caching significantly reduces the load on the Kubernetes API server. By storing SHA hashes of resource manifests, apply configurations, and server states, we avoid redundant API calls. This results in faster reconciliation loops and quicker application of changes, especially noticeable when managing numerous resources across a large fleet. The cache also mitigates potential issues related to CRD lifecycle management and client-side throttling.
What are the key considerations for scaling GitOps in a multi-cluster environment?
Scaling GitOps requires careful consideration of resource consumption, latency, and race conditions. Resource consumption can be amplified by admission controllers used by various Kubernetes components. Latency can be introduced by server-side applies and status updates. Race conditions can arise from parallel processing of resources. Plural's architecture addresses these challenges through its distributed agent model, optimized caching, and efficient resource application logic.
How does Plural address the security vulnerability (GO-2025-3437) associated with the GitOps Engine?
Plural exclusively uses patched versions of the GitOps Engine to mitigate the risk of exposed secrets in patch errors. We continuously monitor for and address any new vulnerabilities to ensure the security of our platform and protect sensitive information.
What are the advantages of using a dedicated GitOps solution like Plural compared to general-purpose tools?
While general-purpose tools offer basic GitOps functionality, Plural provides a specialized platform tailored for managing large fleets of Kubernetes clusters. This includes features like simplified configuration across multiple clusters, efficient bulk resource application, and a secure, scalable architecture designed for enterprise environments. Plural's focus on fleet management allows for streamlined workflows and optimized performance at scale, addressing the specific needs of platform engineering teams.

Newsletter
Join the newsletter to receive the latest updates in your inbox.








{kind=link}